Chapter 1: ML Problem Framing
Start with the business outcome, then work top-down: business objective → product outcome → model goal → decision policy. If those four layers do not line up, no model improvement will save the system.
Framing determines whether any later modeling work matters. Most production ML failures happen because teams define the wrong problem, optimize the wrong proxy, or choose a decision policy that cannot move the business outcome.
Here is something counterintuitive: most ML projects do not fail because the model is wrong. They fail because the team aimed the model at the wrong thing.
The model metric looks fine, offline evaluation passes, and the engineers are proud of what they built. But the product does not improve. The business KPI does not move. Six months of work delivers nothing observable.
This is a framing failure, and it is the most common way ML projects die.
What framing actually means
Framing is the work you do before you touch any data. It is the process of defining what success looks like at every layer of the system: the business, the product, the model, and the decision.
Most teams skip this, or do it too quickly. They get a request ("build a churn model," "add a recommender," "detect fraud") and jump straight to feature engineering. The problem is that those phrases do not define a system. They define a modeling idea. There is a large gap between the two.
Think of it this way: imagine a team proudly building the best turn-by-turn navigation engine in the world before anyone agrees on where the car should go. The routing can be fast. The maps can be detailed. The voice assistant can be polished. None of it matters if the destination is wrong or undefined.
ML problem framing is the work of agreeing on the destination.
The framing stack
The most useful tool for framing is a four-layer stack. Each layer constrains the next. Work top-down. Do not jump to layer 2 until layer 1 is solid.

Level 0 — Business objective
State the business problem in one sentence and one metric with a timeframe.
- Reduce monthly churn by 8% in two quarters
- Increase first-purchase conversion by 5%
- Cut fraud loss by $2M this year
If you cannot name a measurable KPI and timeframe, you do not have an ML project. You have a wish.
Level 1 — Product outcome
Describe what the product or workflow should do differently once ML exists. This is where the system becomes concrete.
- Rank items so relevant ones appear earlier in the feed
- Route support tickets to the right team faster
- Flag risky transactions before approval
Notice what changed: it is no longer "use AI." It is "change this product behavior in this observable way." That is a thing you can test.
Level 2 — Model goal
Define what the model should estimate so the product can create that outcome.
- Probability a user buys this item (not "build a recommender")
- Probability a support ticket belongs to billing (not "classify tickets")
- Probability a transaction is fraudulent (not "detect fraud")
This is the prediction layer. It is not the final business goal. It is one step in the chain.
Level 3 — Decision policy
Define how the prediction turns into a real action. This is the layer most teams forget entirely.
- Show top 10 ranked items
- Send high-confidence tickets directly to a queue; route uncertain ones to triage
- Block transactions above a fraud threshold; send borderline cases to human review
This layer determines whether the prediction is actually useful in practice. A great model that produces predictions nobody acts on is not an ML system. It is a science project.
Running a bad idea through the stack
A vague proposal like "build a churn model" becomes specific and challengeable when you run it through the stack:
- Business objective: reduce churn in the first 90 days by 10%
- Product outcome: identify at-risk users early enough to trigger retention offers
- Model goal: predict probability that a new user churns within 30 days
- Decision policy: if risk score is above threshold, trigger a retention email and show an in-app setup prompt
Now you can ask real questions: Is 30-day churn the right target? Are the retention actions likely to change behavior? Is the prediction early enough to matter? Is the threshold cost-effective?
The framing stack does not answer these questions. It makes them visible so the team can answer them before building anything.
Think about it: Think of an ML feature from your company or a product you use often. Rewrite it as a framing stack: business objective, product outcome, model goal, and decision policy. Do not skip the decision policy — that is where vague ideas usually break.
Expert thinking
A senior engineer would not start by debating architecture. They would first test whether the system is legible across all four layers.
Example: "recommend creators to follow"
- Business objective: improve 30-day user retention for new users
- Product outcome: show each new user a more relevant feed earlier in their lifecycle
- Model goal: predict probability that a user follows and continues engaging with a creator after exposure
- Decision policy: rank candidate creators, show top results during onboarding, and cap repetition to avoid feed collapse
Why this is stronger than "build a recommender": it names the KPI instead of assuming engagement is enough, makes the workflow change explicit, defines a prediction that can be measured, and forces an action policy including constraints.
Self-assessment checklist:
- Did you name one business KPI and a timeframe or context?
- Did you separate the product behavior from the model prediction?
- Did you describe what action happens after the prediction?
- Did you avoid using "accuracy" as the business objective?
Why good offline metrics can still mean nothing
Offline model metrics tell you whether the model predicts its chosen target well on historical data. They do not prove the target was useful, the action policy works, or the user experience improved.
You can have:
- A high-AUCArea Under the ROC Curve: measures classification quality from 0.5 (random guessing) to 1.0 (perfect separation) fraud model that sends so many legitimate users into manual review that the economics are worse than before
- A strong recommender that optimizes clicks but degrades long-term trust and subscription retention
- A precise support classifier that routes tickets correctly, but by the time it fires, the customer has already churned from waiting
The pattern is consistent: the model wins at the narrow task, and the system loses at the broader goal. AUC improved and conversion dropped. That is a framing failure, not a modeling one.
This is why the framing stack matters. Before you tune a model, you need to prove that the prediction, the policy, and the KPI are actually connected.
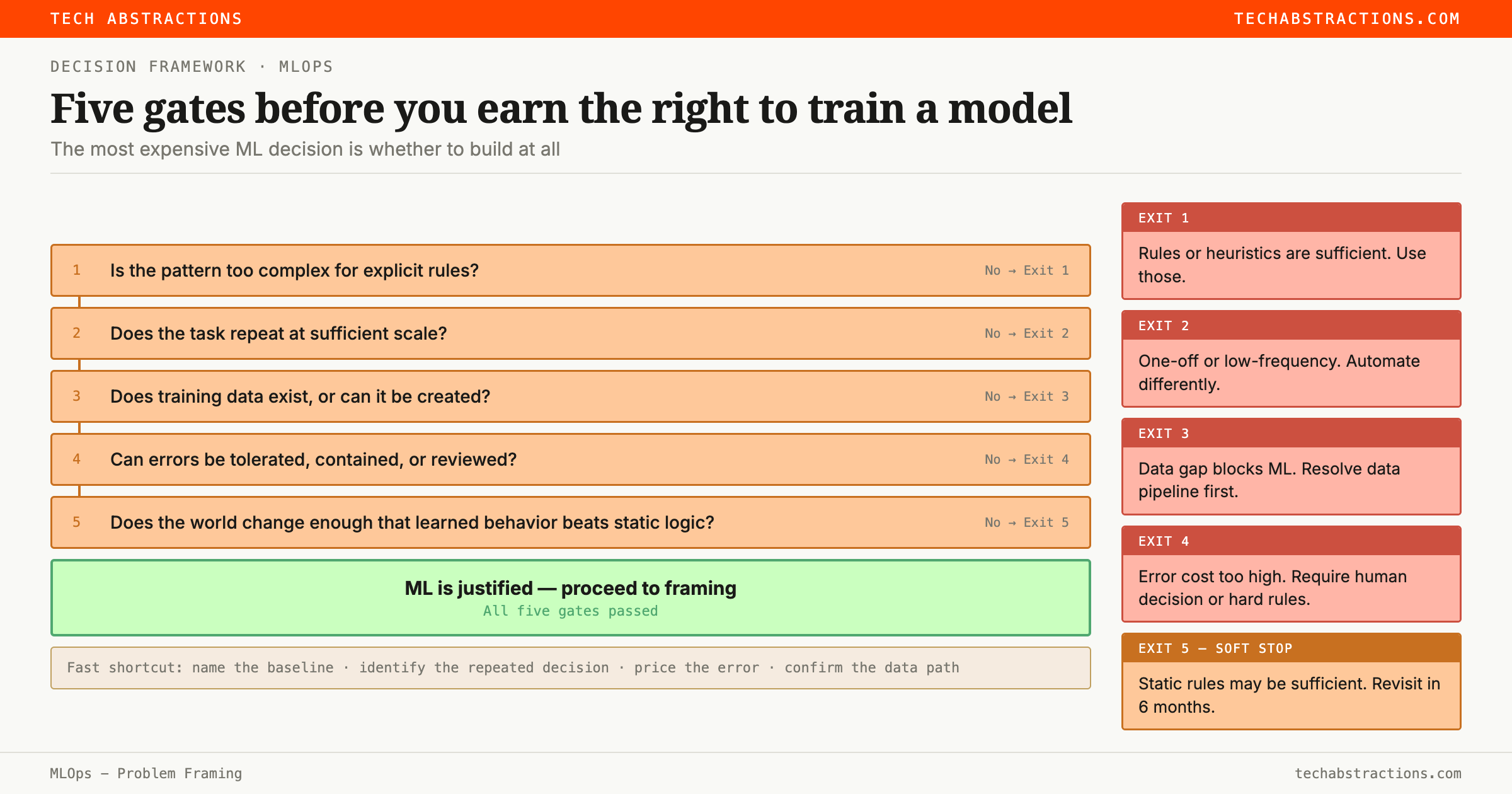
Should you use ML at all?
Before committing to a build, the first honest question is whether ML is the right tool. The answer is often no, and realizing that early is not a failure. It is good engineering.
Use ML when all of these are true:
- The pattern is too complex or too brittle for explicit rules
- The task repeats at enough scale to justify the system overhead
- Data exists, or there is a credible path to create it
- Errors can be tolerated, contained, or reviewed
- Patterns evolve at a rate that makes rule maintenance impractical
Do not use ML when rules or simple heuristics already work well, when data is weak or blocked, when errors are catastrophic and cannot be contained, or when the maintenance economics do not justify the complexity.
A fast decision sequence: first, name the non-ML baseline (rules, search, manual review, simple statistics). Then identify whether the decision repeats often enough for ML gains to compound. Then price the error cost: what does a false positive or false negative actually cost? Then confirm that the features and labels you need actually exist at serving time.
Teams often justify ML because the problem feels sophisticated. "Interesting" is not a product requirement.
Think about it: A support team wants to route incoming tickets faster. Today they use forms, routing rules, and a small manual triage group. Should they use ML now, later, or not at all? Write your answer in three parts: (1) what baseline you would compare against, (2) one reason ML might help, (3) one reason rules might still be the better decision.
Expert thinking
A strong answer starts with the baseline, not the model.
- Baseline: current routing accuracy, median time to assignment, and percent of tickets needing manual reroute
- Reason ML may help: free-text tickets often contain messy signals that rigid rules miss, and volume may justify automated classification
- Reason rules may still win: if ticket categories are stable, forms are structured, and volume is moderate, better forms plus a few routing rules may deliver most of the value at lower operational cost
The real decision is not "can a classifier work?" It is "is the classifier the cheapest reliable way to move the KPI?"
Self-assessment checklist:
- Did you compare ML to a real baseline?
- Did you mention data shape or decision volume?
- Did you include operational cost, not just model quality?
- Did you avoid assuming ML is automatically the advanced option?
The three ML product archetypes
Once you decide ML belongs, you need to decide how autonomous the system should be. This is not a modeling question. It is a risk and product design question.
Automation augmentation: the model replaces or augments deterministic logic. The system can outperform rules on a repetitive decision and still fall back safely. Success is measurable uplift against the baseline. Guardrails usually include confidence thresholds and hard business rules.
Human-in-the-loop: the model assists humans rather than acting alone. Use this when judgment matters, errors are costly, or you need to build trust before handing off decisions. Success is measured in time saved, queue quality, and lower human error rates.
Autonomous: the model acts without a human in the loop. Use only when latency, scale, or economics require direct action and failure can be tightly contained. Success here means failure rate, rollback readiness, and auditability, not accuracy alone.
The rule of thumb: the more autonomous the system, the more the engineering roadmap becomes risk management, monitoring, rollback, and policy design, not model tuning.
Think about it: You are designing an invoice anomaly system for finance operations. Should it be automation augmentation, human-in-the-loop, or autonomous? Explain: (1) the likely error cost, (2) which archetype you would start with, (3) what would have to be true before you moved to a more autonomous mode.
Expert thinking
A prudent starting point is human-in-the-loop.
Invoice anomalies often involve money movement, vendor trust, and compliance risk. False positives create review overhead, but false negatives can create financial exposure. A model can rank or flag suspicious invoices well before it should auto-block or auto-approve them.
To move toward autonomy, you would want: stable historical performance across segments, clear policy thresholds, proven reviewer agreement on high-confidence cases, and rollback and audit mechanisms.
This is a framing question because the archetype determines what "good enough" means. A model that is accurate enough for human-assisted review may not be safe enough for autonomous action.
Self-assessment checklist:
- Did you tie the archetype to error cost?
- Did you mention human workflow, not just the model?
- Did you specify what evidence would justify more autonomy?
Choosing proxy labels — where good systems go wrong
The true outcome you care about is almost never directly observable. The system cannot directly observe "useful content," "high purchase intent," or "trustworthy answer." So it reaches for a proxy.
This is where many good-looking systems go quietly wrong.
Rate each candidate proxy labelProxy label: an observable signal used as a stand-in for an outcome the system can't directly measure. Example: click-through rate as a proxy for 'content users find genuinely useful'. on five dimensions: how close is it to the real outcome (alignment)? Does optimizing it encourage bad behavior (gaming resistance — higher score means safer)? Do you get enough labels across important segments (coverage)? How quickly does the label arrive (latency)? If this proxy improves, is the KPI likely to move (causal usefulness)?
| Ideal outcome | Proxy you might reach for | What goes wrong |
|---|---|---|
| Useful content | Click | Sensational content wins attention, degrades trust |
| Purchase intent | Add-to-cart | Many carts never convert |
| Quality answer | Thumbs-up | Only a small, biased group of users rates |
The heuristic: sparse-but-aligned is almost always better than abundant-but-misleading. The easiest label to collect often has the most dangerous incentives baked in. Once the system is live, those incentives become product behavior.
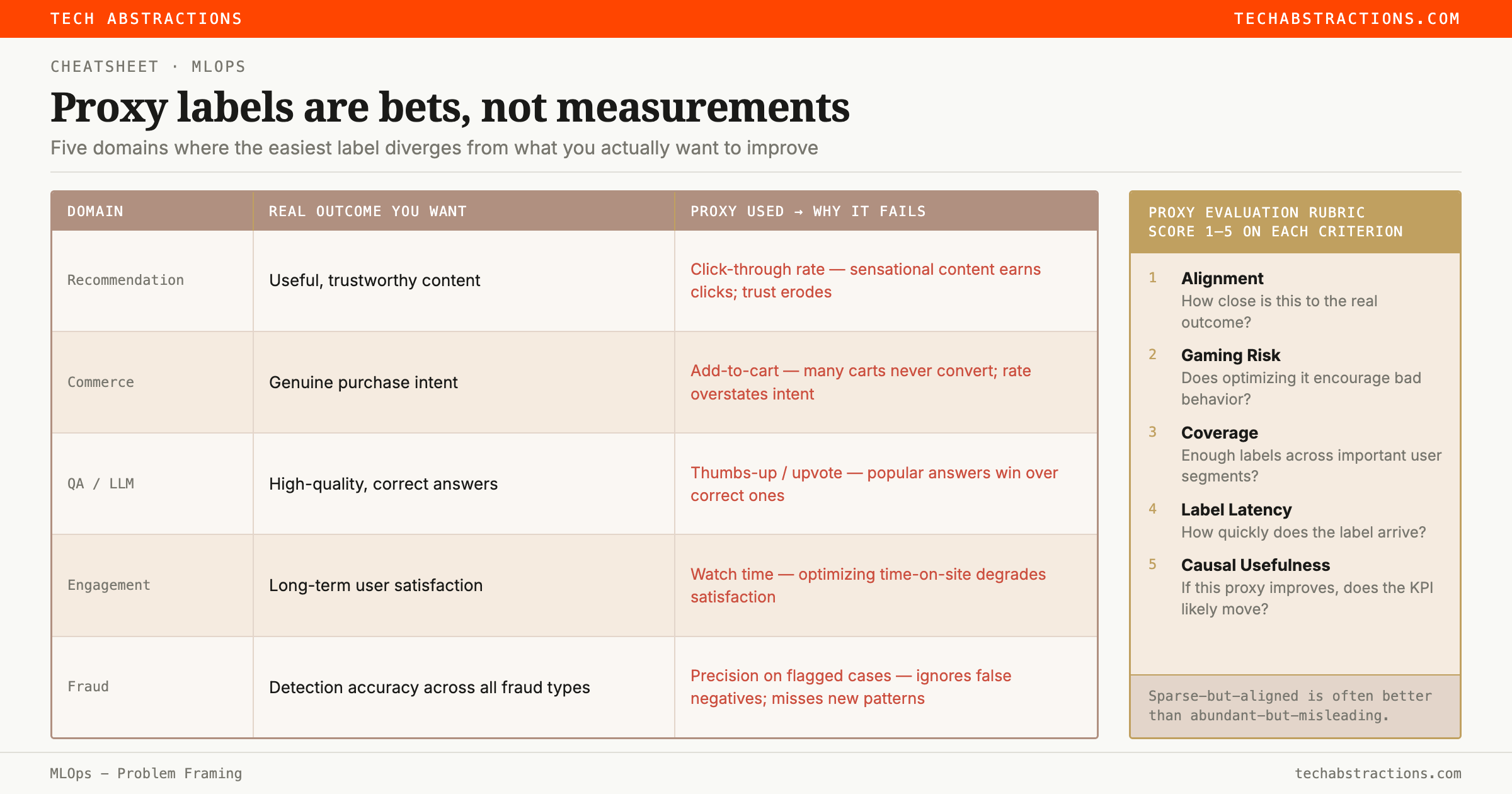
Think about it: Pick a product you use regularly that has a recommendation, ranking, or content feed. Identify the proxy label the system is most likely using. Score it on the five dimensions: alignment, gaming risk, coverage, latency, and causal usefulness. Which dimension is its biggest weakness, and what would a better proxy look like?
Expert thinking
A strong answer does not just name a proxy — it reveals the tradeoff structure.
Example: an e-commerce product feed most likely optimizes for click-through rate.
- Alignment (2/5): click measures attention, not intent. Many clicks end in zero-second bounces.
- Gaming resistance (1/5 — low resistance, high gaming risk): the system quickly learns that thumbnails, titles, and price anchoring drive clicks more than product relevance. Clickbait wins.
- Coverage (5/5): dense signal available for all items and users.
- Latency (5/5): immediate signal, no lag.
- Causal usefulness (2/5): click uplift does not reliably predict purchase uplift, especially when users are browsing rather than buying.
Better proxy: a weighted combination of short-dwell-click (filter out bounces), add-to-cart, and purchase — with explicit downweighting of sessions where all three diverge from each other.
Self-assessment checklist:
- Did you score all five dimensions, not just name the proxy?
- Did you identify the single biggest weakness?
- Did you propose a more aligned alternative, not just "better data"?
What can kill a production ML system before it ships
Many projects that look promising in a notebook die in production. The notebook hides the operating environment.
Eight common failure points:
- Label scarcity or severe class imbalance
- Features not available at serving time (training-serving skewTraining-serving skew: when a feature used during model training is unavailable, stale, or computed differently at serving time — causing silent model degradation in production)
- Latency or throughput requirements the architecture cannot meet
- Error cost underestimated — false positives or negatives are more expensive than expected
- Distribution shiftDistribution shift: when the statistical patterns in production data differ from those in training data — due to seasonality, new user cohorts, product changes, or evolving behavior from seasonality, new users, new products, or behavior changes
- Adversarial behavior — fraud patterns or spam adapt to the model
- Compliance, privacy, or legal constraints that block the feature set
- No real owner, monitoring budget, or operating model post-launch
The most silent killer is training-serving skew. It is primarily a data pipeline bug — the feature you trained on only exists in the offline dataset. At serving time, it is unavailable, delayed, or computed differently. The model degrades and nobody knows why. It is also a framing oversight: the system was designed around features that only existed offline.
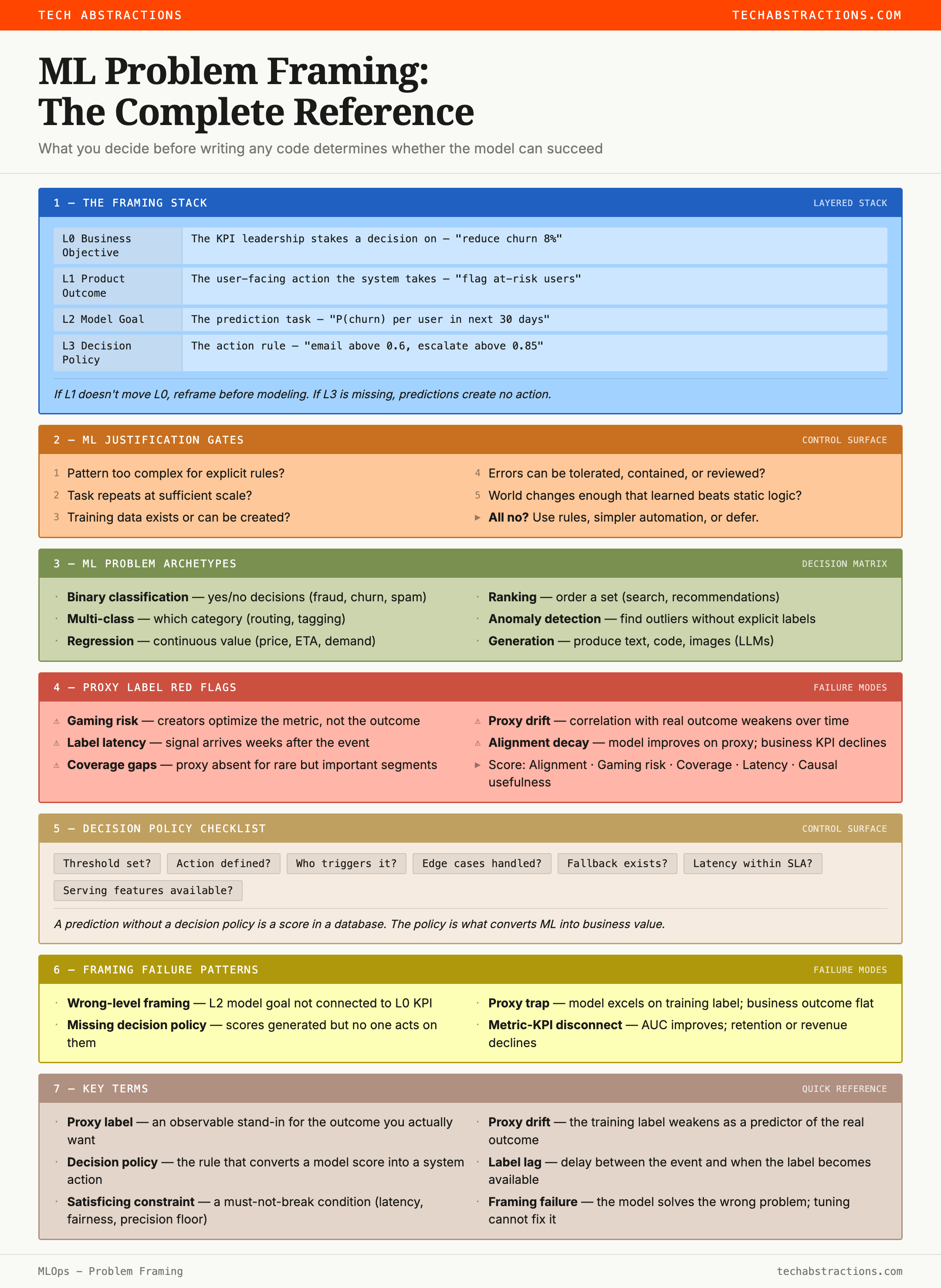
How to measure the right things
Keep three layers of measurement separate and never collapse them into one:
Business KPI — what leadership or the product owner cares about. Retention. Revenue. Error rate. Something that moves money or users.
Model metric — how well the model performs on its prediction task. PrecisionPrecision: of all cases the model flagged positive, the fraction that were truly positive. High precision means few false alarms., recallRecall: of all actual positives in the data, the fraction the model correctly identified. High recall means few misses., AUCArea Under the ROC Curve: measures classification quality from 0.5 (random guessing) to 1.0 (perfect separation), NDCGNormalized Discounted Cumulative Gain: a ranking quality score that rewards putting the most relevant results first, and penalizes relevant results buried lower in the list. This is an internal signal, not a business result.
Satisficing constraintsSatisficing constraints: must-not-break conditions. From Herbert Simon's idea of satisficing — meeting a threshold rather than maximizing. The system must stay within these bounds, but doesn't need to optimize them. — conditions the system must not violate. Latency under 200ms. Precision above 0.9 on the high-stakes segment. Fairness check passing. Review-load staying below what the ops team can handle.
Pick one primary model metric. If you have conflicting objectives (quality, engagement, safety), score them separately and combine them in the decision policy. Do not try to encode every tradeoff inside one opaque objective function.
What's next: Advanced Practice
The free section above covered the core framing concepts and tested them with basic apply exercises. The advanced section below goes further — messier scenarios, harder tradeoffs, production edge cases, and interview-style pressure tests.
Advanced Exercise preview: You inherit a 3-year-old fraud model. Offline metrics look healthy, but false positive rates have crept up on a specific user segment over the past quarter. Your manager wants a quick fix. The right answer may not be what they expect...
Production Challenge preview: A team's churn model passed every offline eval. The live experiment showed zero retention improvement for 8 weeks. The postmortem revealed three compounding failures — none of them in the model itself. Walk through the diagnosis chain...
Interview Reasoning preview: A VP asks you to justify why the team is spending 3 months on problem framing before training any model. You have 5 minutes and a skeptical audience. How do you make the case without getting lost in ML terminology?
Subscribe to unlock the full advanced practice section.
Advanced Applied Exercises
Exercise 1 — The Inherited Mess
You join a team that has a production fraud model deployed for 3 years. Offline AUC is 0.94. But false positive rates have increased 40% on a specific user segment (new signups from mobile) over the past 6 months, while overall metrics look fine. Your manager wants you to "tune the threshold."
What would you actually investigate? Walk through:
- Why threshold tuning may not fix the root cause
- The three most likely explanations for segment-specific degradation
- What data you would pull before changing anything
- What you would escalate vs. fix yourself
Expert thinking
Threshold tuning is a band-aid. The right questions are: why did this segment change, and why did the overall metric hide it?
Why the overall metric can look fine while a segment degrades: this is a classic aggregate-masking pattern (sometimes called Simpson's Paradox). If the mobile signup segment is small relative to the overall user base, its worsening performance can be overwhelmed by the stable majority, leaving the aggregate AUC unchanged. This is why per-segment monitoring is not optional — aggregate metrics can hide real production failures for months.
Three most likely root causes:
- Distribution shift on mobile signups — new user acquisition channels changed the feature distribution for this segment. The model learned on older mobile behavior that no longer applies.
- Feature staleness — a feature used heavily for mobile users is now stale or computed differently (app version, device fingerprinting, session behavior).
- Label leakage or proxy drift — fraud patterns in this segment changed, but the proxy label hasn't caught up (e.g., fraud complaints lag actual fraud by weeks).
Before changing anything: pull per-segment performance over time (not just 6 months, but the full 3-year history). Look for when the degradation started. Cross-reference with product changes (new sign-up flow?), data pipeline changes, and feature computation changes. Check whether the segment definition itself changed.
What to escalate: if the root cause is a feature pipeline change that affects serving-time data, that is an engineering dependency, not a model fix. Escalate immediately — threshold tuning on top of corrupted features makes things worse.
Self-assessment checklist:
- Did you reject threshold tuning as the first step?
- Did you name distribution shift or feature drift as a hypothesis?
- Did you note that aggregate metrics can mask segment-level degradation?
- Did you specify what data you would pull before acting?
- Did you distinguish model problems from data pipeline problems?
Exercise 2 — The Multiclass Scaling Trap
A team wants to predict "which product each user will buy next" across a catalog that adds 500 new SKUs per week. They have framed this as a 50,000-class multiclass classifier. They are 2 months into training and the model is already showing performance decay on new items.
What is wrong with the framing, and what would you change?
Give: your preferred reframing, one reason it scales better, one tradeoff it introduces, and what the team should do with the existing 2 months of work.
Expert thinking
The framing is wrong at the task definition level, not the model level.
Preferred reframing: predict an interaction or purchase score for each user-item pair, then rank candidates. The model output is a scalar — not a class label — so new items enter through features rather than requiring a new output class.
Why it scales better: new SKUs can be represented by their feature embeddings (category, price, description, seller history) without retraining the output layer. The model generalizes to new items via features, not by memorizing IDs.
Tradeoff introduced: you now depend heavily on candidate generation quality and feature freshness. If the candidate retrieval step misses relevant new items, the ranker never sees them. This is a retrieval problem, not a ranking problem — a different failure mode.
What to do with 2 months of work: the training data (user-item interactions) is reusable. The model architecture needs to change (from multiclass head to scoring model). Roughly 2 weeks of reframing vs. continued degradation for months. Worth the reset.
Self-assessment checklist:
- Did you identify the output class explosion as the root problem?
- Did you name a score-based approach as the fix?
- Did you mention candidate generation as a new dependency?
- Did you address what to do with existing work?
Exercise 3 — Proxy Label Under Cross-Examination
You are presenting a proxy label choice to a skeptical VP of Product. You have chosen "30-day completion rate" as the proxy for "educational value" in a video learning platform.
She asks three questions: (1) How do you know completion predicts learning, not just short video preference? (2) What happens to the model's behavior if we optimize this proxy for 12 months? (3) What would have to be true for you to change the proxy in production?
Answer all three as you would in the room.
Expert thinking
These are exactly the right questions. Here is how to answer them without losing the room.
(1) How do you know completion predicts learning? You don't know for certain — that is the honest answer. What you do know is that completion correlates with user satisfaction signals in historical data (cross-referenced with exit surveys and return visit rates). It is a proxy, not a measure. The bet is that users who complete content found it valuable enough to finish. You would add explicit quality signals (post-video ratings, quiz performance if available) alongside completion to triangulate. State the bet clearly; do not pretend it is ground truth.
(2) What happens after 12 months of optimization? The model will learn to favor shorter videos and easier content — both complete at higher rates. It will also learn to favor popular creators whose editing is tighter. This may reduce average difficulty, reduce content diversity, and create feedback loops that disadvantage niche but valuable content. You should monitor: average content difficulty trend, creator diversity index, and explicit quality survey scores over time.
(3) What would make you change the proxy? Three signals: (a) the correlation between completion and explicit quality ratings drops below threshold; (b) content diversity metrics fall faster than acceptable; (c) A/B tests show that higher-completion models produce lower subscription renewal rates. Any one of these would trigger a proxy review.
Self-assessment checklist:
- Did you acknowledge the proxy's limitations honestly?
- Did you name a concrete long-term risk of optimizing it?
- Did you specify measurable triggers for reconsidering the proxy?
Real-World Implementations
Production Teardown — A Home-Rental Marketplace's Search Ranking Reframe (Illustrative)
A major home-rental marketplace's early search ranking system optimized for booking conversion rate — the most direct business signal. The problem: the model learned that accepting any booking was better than no booking, which led to hosts accepting bookings they later cancelled, guests being left without accommodation, and trust damage that took quarters to repair.
The reframe: the team shifted the primary objective from booking conversion to "successful trip completion" — a composite signal that included booking, no cancellation, no serious host/guest issues, and positive review. This required combining signals that arrived at different times (some only after the trip), which created a significant label lag measured in weeks.
The architectural tradeoff: a multi-week label lag means the model is always training on behavior from several weeks ago. In a fast-moving marketplace, this creates distributional lag. The team handled it by training on lagged labels for the primary objective but using faster proxies (like listing quality score and host response time) as features — not as the objective.
Discussion: where else does objective lag create model risk? What is the maximum lag that is acceptable for a primary objective, and how do you decide?
Production Teardown — A Professional Network's "Should We Use ML?" Discipline (Illustrative)
A professional network's feed ranking team encountered a case where a simple rules-based approach — "show the 20 most recent posts from your connections" — outperformed an early ML-based feed ranker on the primary engagement metric for several weeks after launch.
The ML model was not wrong. It was predicting the right thing. But the baseline was stronger than expected, the training data had label noise from the old system's behavior, and the model needed more data to learn stable patterns. The team had the discipline to wait, collect data in shadow mode, and launch only when the model could consistently beat the baseline.
The lesson: baselines are not embarrassments. They are the comparison point that makes "ML works" meaningful. Every ML project should have one.
Production Challenges
Incident Postmortem — The KPI That Did Not Move
A churn model was accurate in offline evaluation. The live retention experiment ran for 8 weeks and showed no improvement. Postmortem revealed three compounding failures, none of them in the model itself.
Failure 1 — Action timing: the model fired a retention email 3 days after the user's last session. By that point, users who were going to churn had already mentally disengaged. The intervention needed to fire within 24 hours of the first missed engagement signal.
Failure 2 — Action quality: the retention email offered a 10% discount. Churn analysis showed the primary reason for early churn was confusion about the product, not price sensitivity. The discount addressed the wrong problem.
Failure 3 — Measurement window: the experiment measured 30-day retention. Churn from this segment actually played out over 60–90 days. The experiment ended before the effect (positive or negative) could be observed.
Your diagnosis: for each of the three failures, identify what framing decision earlier in the project would have caught it, and what the fix is going forward.
Interview-Style Reasoning Questions
Question 1 — Defending the framing phase
A VP asks: "Why is the team spending 3 months on problem framing before training any model? We have a dataset, we have engineers, let's just start." You have 5 minutes. Make the case.
Model answer
Do not defend framing as a process. Defend it as risk management with a known failure rate.
Opening: "The most expensive ML work is work that has to be thrown away. The number one reason ML projects get thrown away is not model quality — it is that the system was aimed at the wrong target. Most of them fail at this stage — not because engineers lacked skill, but because the problem was never framed clearly enough."
Middle: "Three months on framing saves 12 months of the wrong build. We have seen this with [internal example or well-known public example]. The churn model that improved AUC but didn't move retention. The recommender that increased clicks but degraded subscription renewals. In both cases, the problem was identified at framing — but only in retrospect, after the build."
Close: "What we are doing in these 3 months is confirming that the prediction we are planning to build is causally connected to the business outcome we care about. If it is not, we find that out now, not in 9 months. That is the value."
Self-assessment checklist:
- Did you lead with business risk, not methodology?
- Did you use a concrete example of what goes wrong without framing?
- Did you quantify the cost comparison (3 months now vs. 12 months wasted)?
Question 2 — System design under constraints
You are designing a real-time content moderation system. It needs to handle 100,000 posts per minute, make a blocking decision in under 50ms, and achieve less than 0.1% false positive rate on the post stream (posts wrongly blocked). Walk through how you would frame this problem before writing any model code.
Model answer
This is a constraint-dominated framing problem. Start by identifying which constraints are hard and which are soft.
Hard constraints: 50ms latency at 100K/minute is the binding constraint. Any model architecture that cannot serve at this rate with this latency budget is not a solution, regardless of accuracy. Start here.
The false positive budget: 0.1% on 100K posts/minute = 100 wrongly blocked posts per minute, or roughly 144,000 per day. That is a very large daily error count. Is human review the downstream action, or is it an automated block? If it is an automated block, 144,000 daily errors is almost certainly not acceptable — reconsider the requirement as a business decision before optimizing toward it.
Framing the task correctly: content moderation is rarely a single model problem. It is a multi-stage pipeline: (1) fast cheap filters that catch obvious violations (rules-based, embedding similarity), (2) a medium-latency model for ambiguous cases, (3) human review queue for edge cases and appeals. Frame each stage separately with its own objective, latency budget, and error cost.
What you would not build first: a single end-to-end model handling all 100K posts per minute with per-request 50ms latency. That is impractical and extremely expensive at any reasonable accuracy level — the throughput alone requires significant horizontal scaling before you can think about model quality. The framing reveals that.
Self-assessment checklist:
- Did you identify the latency constraint as the binding architectural constraint?
- Did you question the false positive requirement as a business decision, not just a model parameter?
- Did you propose a multi-stage pipeline rather than a single model?
Question 3 — Detecting silent framing failure
Your fraud model's AUC has been stable at 0.91 for two months. No alerts have fired. But fraud losses have been creeping up 3-4% per month for six weeks. Name three production signals that would tell you whether this is a framing or proxy failure (not a model accuracy failure), and describe how you would triage them.
Model answer
Stable AUC with worsening business outcomes is the signature of proxy divergence or a new fraud type outside the model's training distribution — not a model accuracy failure.
Signal 1 — Proxy-to-outcome correlation drift: Plot the correlation between the model's fraud score and confirmed fraud events over the past 12 weeks. If AUC is stable but this correlation is declining, the model still rank-orders its training distribution correctly, but the actual fraud population has shifted away from what the model was trained to detect. This is proxy divergence.
Signal 2 — Per-segment loss concentration: Break down fraud losses by user segment, transaction type, and fraud category. If losses concentrate in a narrow segment (new users, mobile, high-value), that segment is the diagnostic location — it may be experiencing a new fraud pattern the model was not trained on.
Signal 3 — False negative composition on confirmed fraud: Pull confirmed fraud cases from the past 6 weeks and check what fraction the model scored below threshold. If false negatives cluster in a specific category (synthetic identity, account takeover), the model is systematically missing a new fraud type, not failing on its training distribution.
Triage sequence: Start with Signal 2 (where are losses concentrated?), then Signal 1 (is the proxy still correlated with losses in that segment?), then Signal 3 (what does the model score on confirmed fraud in that segment?). Run from business signal to proxy signal to model signal — not from model outward.
What threshold tuning does not fix: Lowering the threshold makes the model more aggressive globally. If the root cause is a new fraud type that scores far below any reasonable threshold, lowering the threshold adds false positives on legitimate transactions without catching the new fraud. Threshold tuning is a last resort, not a first response.
Self-assessment checklist:
- Did you distinguish framing/proxy failure signals from model accuracy signals?
- Did you propose at least two signals that surface proxy divergence specifically?
- Did your triage sequence start from the business signal, not the model signal?
- Did you explain why threshold tuning is the wrong first response?
Unlock Premium Access to access this content.
This chapter has 3 premium workbook exercises. Unlock Premium Access to practice and compare with expert reasoning.
$49 one-time — lifetime access